
Research
About My Research
My current research focus is on building trustworthy, causal and robust stats/ML models for decision making and inference. A lot of fancy terms but the overarching goal is to build nice reliable statistical models that give good insights.
Trustworthy:
‘Trustworthiness’ is a broad term that has various facets and can be subjective in practice. In order to study trustworthiness in context of machine learning, I have focused on competence based theories of trust. Here, trust is framed as reliance on a machine or model’s capability to achieve its goals. In the context of predictive models and decision-making, this notion translates into our reliance on a model that consistently demonstrates competence in achieving its goal in a decision-making task. Suppose, a data scientist is interested in using classification models for making some decisions (eg. to give loan or not) and wishes to understand which model (Logistic Regression, XGboost, Neural Networks etc) can be considered ‘trustworthy’. There are multiple choices and often different metrics pick different models.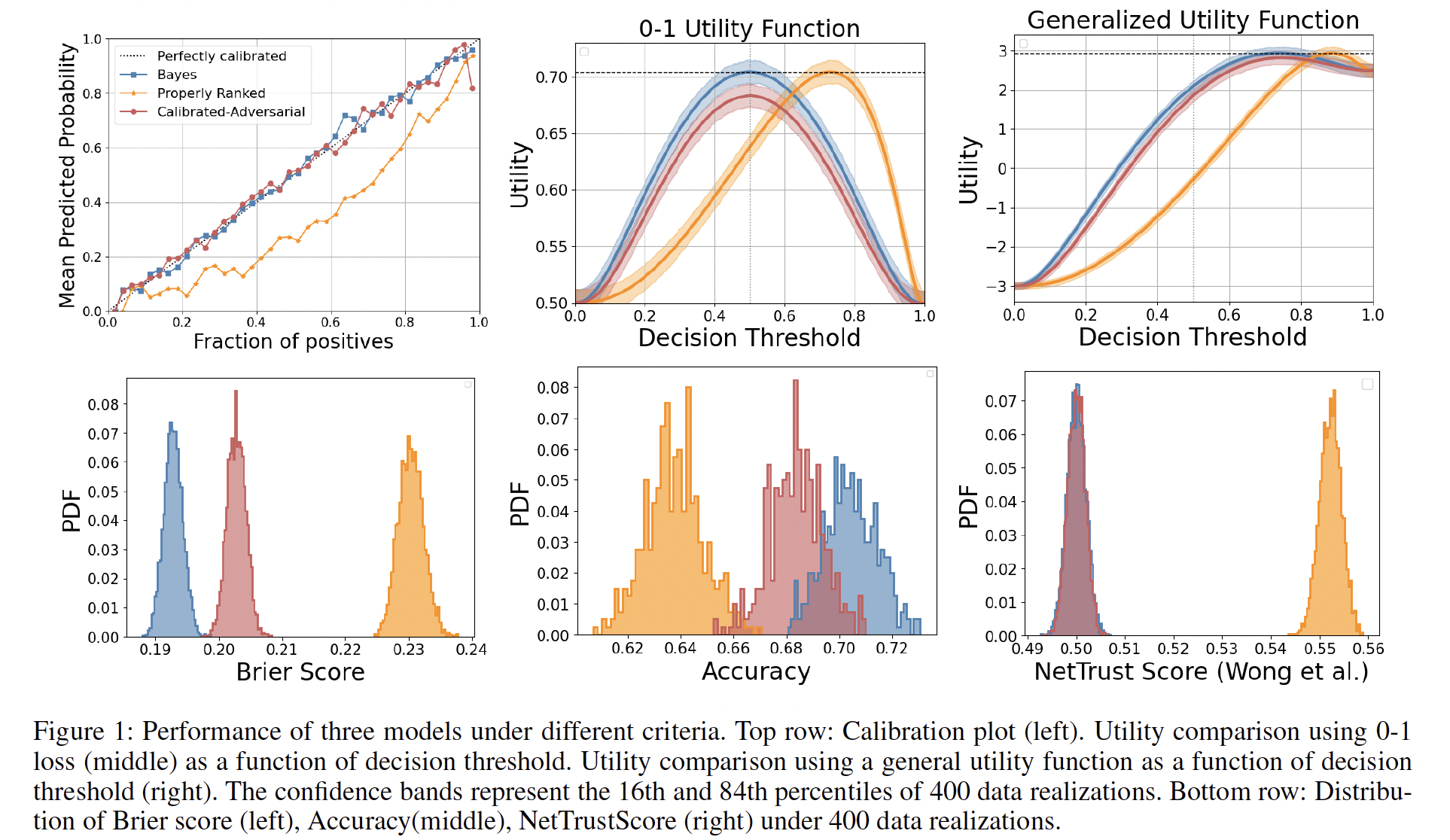
Figure 1 from U-Trustworthy Paper
In U-trustworthiness, we develop a mathematical framework that evaluates the claim of whether “B is trustworthy to do X,” where B is a predictive classification model, and X is a subset of decision-making tasks. We show that for purpose of decision making where utility maximization is the primary goal, ‘properly-ranked’ models can be considered ‘trustworthy’ (See Theorem 2). We also show how AUC may be used as a measure of competence (See Theorem 5).
Now suppose the data scientist wishes to estimate the amount of loan to be given to an approved applicant. Here, the data scientist may also want to make sure that the model takes into account the income such that for approved applicants, estimated loan amount is higher for applicants with higher income. In this case, the goal is not ‘decision making’ anymore but to ‘infer’ from data. In such similar cases, where goal is to do ‘inference’, we show in I-trustworthiness that how local calibration is needed to ensure that model is ‘competent’ for doing inference. We provide a statistically valid metric and a hypothesis test that can help a user evaluate if their model is locally calibrated with respect to some variables in their dataset.
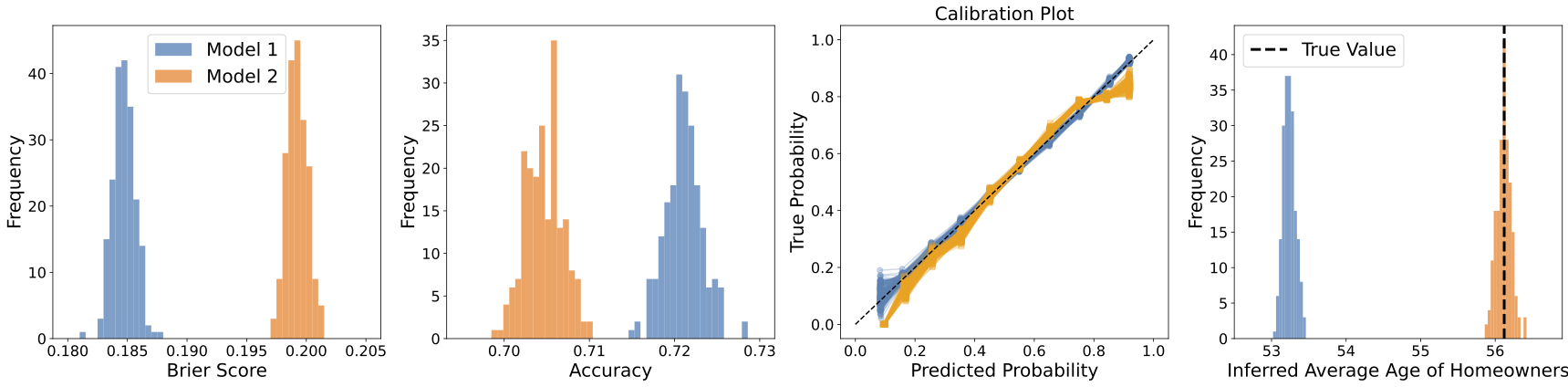
Figure 1 from I-Trustworthy Paper. Consider the task of inferring the average age of homeowners when homeownership status is unknown (test sample), using two models that assign probabilities of homeownership. While Model 1 (blue model) outperforms Model 2 in terms of accuracy, Brier score, and ECE, only Model 2 provides an unbiased estimate of the inference target (right panel). The histograms are based on 200 realizations of test/train samples. }